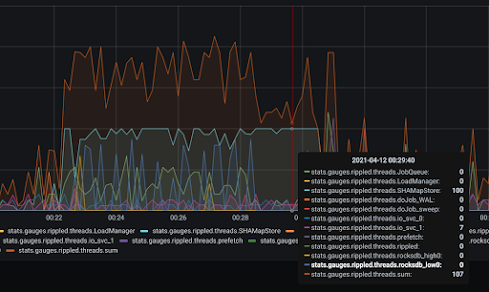
xrp.ninja Ripple validator crashed last night due to low free disk space

The above graph shows what happened.
I did get an alert from GCE that disk usage was high. I have an alert policy which says alert me if disk usage is over 80% for more than 5 minutes. However, it was too late, so I didn't get up and thought maybe it could resolve on its own. But it didn't. And GCE didn't keep alerting me, which surprises me.
Rippled logged these two lines before it died:
2018-Jan-10 11:33:27 Application:FTL Remaining free disk space is less than 512MB
2018-Jan-10 11:33:27 Application:FTL Application::onStop took 23ms
So rippled killed itself:
Before that, log was flooded with the following messages for 5 hours:
2018-Jan-10 10:55:08 LoadMonitor:WRN Job: recvGetLedger run: 1390ms wait: 0msSo it kept getting new ledgers and wrote to the db, till it filled the partition and killed itself.
2018-Jan-10 10:55:32 LoadMonitor:WRN Job: recvGetLedger run: 1250ms wait: 0ms
2018-Jan-10 10:55:32 LoadMonitor:WRN Job: recvGetLedger run: 1533ms wait: 0ms
2018-Jan-10 10:55:32 LoadMonitor:WRN Job: recvGetLedger run: 0ms wait: 1534ms
2018-Jan-10 10:55:33 LoadMonitor:WRN Job: recvGetLedger run: 712ms wait: 1230ms
2018-Jan-10 10:55:33 LoadMonitor:WRN Job: recvGetLedger run: 0ms wait: 1937ms
2018-Jan-10 10:55:33 LoadMonitor:WRN Job: recvGetLedger run: 0ms wait: 1927ms
2018-Jan-10 10:55:33 LoadMonitor:WRN Job: recvGetLedger run: 0ms wait: 1927ms
2018-Jan-10 10:55:33 LoadMonitor:WRN Job: recvGetLedger run: 0ms wait: 1927ms
2018-Jan-10 10:55:33 LoadMonitor:WRN Job: recvGetLedger run: 2ms wait: 1922ms
2018-Jan-10 10:55:33 LoadMonitor:WRN Job: recvGetLedger run: 0ms wait: 1924ms
2018-Jan-10 10:55:33 LoadMonitor:WRN Job: recvGetLedger run: 0ms wait: 1922ms
2018-Jan-10 10:55:33 LoadMonitor:WRN Job: recvGetLedger run: 0ms wait: 1918ms
2018-Jan-10 10:55:33 LoadMonitor:WRN Job: recvGetLedger run: 0ms wait: 1913ms
2018-Jan-10 10:55:33 LoadMonitor:WRN Job: recvGetLedger run: 0ms wait: 1909ms
2018-Jan-10 10:55:33 LoadMonitor:WRN Job: recvGetLedger run: 0ms wait: 1897ms
2018-Jan-10 10:55:33 LoadMonitor:WRN Job: recvGetLedger run: 0ms wait: 1897ms
2018-Jan-10 10:55:33 LoadMonitor:WRN Job: recvGetLedger run: 0ms wait: 1890ms
2018-Jan-10 10:55:33 LoadMonitor:WRN Job: recvGetLedger run: 0ms wait: 1890ms
I have no idea why it got so many new ledgers, as of now.
I fixed it by resizing the disk, partition and filesystem.
I have also changed the db format from RocksDB to NuDB which I should've done when I first started running it.
Comments